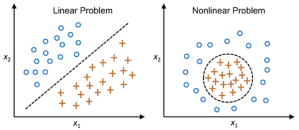
Principal Component Analysis is one of the bread and butter dimensionality reduction methods for unsupervised learning. One of the assumptions of PCA is that the data is linearly separable. Kernal PCA, is a variant of PCA that can handle non-linear data and make it linearly separable. If you wonder what is linearly separable, Python Machine […]
Python
Linear Regression Analysis with statsmodels in Python

Linear Regression is one of the most useful statistical/machine learning techniques. And we have multiple ways to perform Linear Regression analysis in Python including scikit-learn’s linear regression functions and Python’s statmodels package. statsmodels is a Python module for all things related to statistical analysis and it provides classes and functions for the estimation of many […]
Introduction to Data Cleaning with Pyjanitor

Data cleaning is one of the most common and important tasks of any data analysis. In typical data analysis setting, we would might get our dataset from excel/csv/tsv file and perform a series of operations to make the data cleaner. For example, we would start with cleaning the names of variables to make it consistent, […]
Introduction to Canonical Correlation Analysis (CCA) in Python

Increasingly, we have multiple high dimensional datasets from from the same samples. Canonical Correlation Analysis aka CCA is great for scenarios where you two high dimensional datasets from the same samples and it enables learning looking at the datasets simultaneously. A classic example is audio and video datasets from the same individuals. One can also […]
How To Code a Character Variable into Integer in Pandas

Often while working with a Pandas dataframe containing variables of different datatypes, one might want to convert a specific character/string/Categorical variable into a numerical variable. One of the uses of such conversion is that it enables us to quickly perform correlative analysis. In this post, we will see multiple examples of converting character variable into […]